3.4
3.3
This section describes how the application compiles stats. For an overview of what statistics are available to administrators and managers, read the Administrator’s Guide.
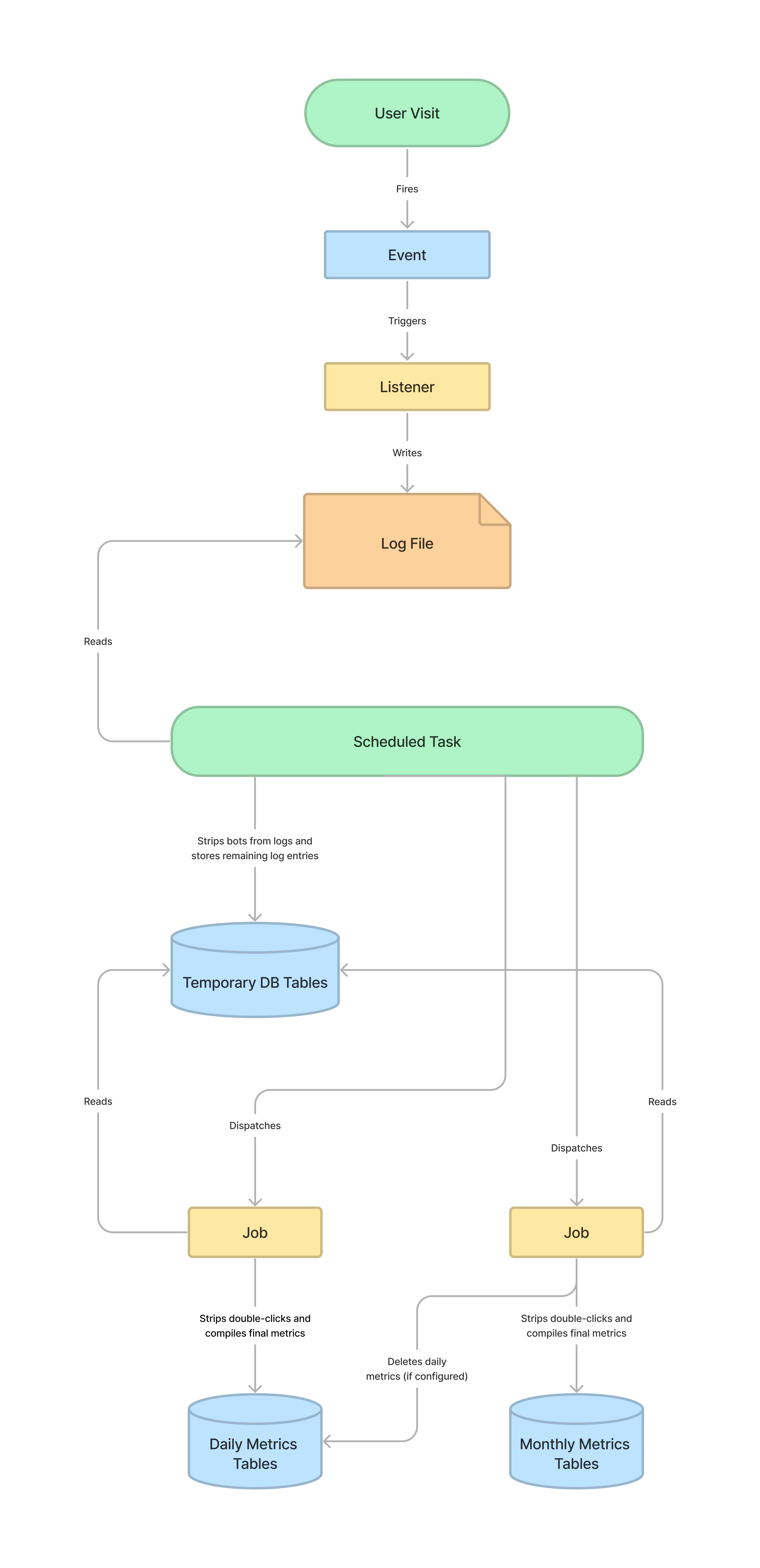
The application provides statistics on the number of users who visit the public website for each journal, press or preprint server. These stats are logged, processed, and compiled into metrics in a series of steps.
When a user visits one of the tracked pages, an event is triggered which logs the visit to a log file in the files_dir. The application then uses scheduled tasks and jobs to process the logs and compile the final metrics. The following diagram describes how this happens.
| Class | Description |
|---|---|
UsageEvent |
The Event dispatched when a user visits a tracked page. The event will include data about what page was visited, such as the Submission and Context. |
LogUsageEvent |
The Listener which anonymizes the IP, determines the user’s geography and institution, and writes to the log file. |
UsageStatsLoader |
The scheduled task which writes to the temporary records tables and dispatches jobs to compile the daily and monthly metrics. |
CompileUsageStatsFromTemporaryRecords |
The Job which compiles the temporary records into the final daily metrics. |
CompileMonthlyMetrics |
The Job which compiles daily metrics into monthly metrics. If the application is configured to only store monthly metrics, it will also delete the daily metrics. |
A log entry is recorded in the log files for each user visit. This entry is a JSON string with information about what was visited, like the context, submission, file, issue, and more. A log entry will look like the following.
{"time":"2023-02-27 11:41:14","ip":"87d8edf8ca58ab4d3e9421b03edcd9c5a2093a79c341964179b8e379faabd324","userAgent":"Mozilla\/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko\/20100101 Firefox\/110.0","canonicalUrl":"https:\/\/example.org\/publicknowledge\/index","assocType":256,"contextId":1,"submissionId":null,"representationId":null,"submissionFileId":null,"fileType":null,"country":null,"region":null,"city":null,"institutionIds":[],"version":"3.4.0.0","issueId":null,"issueGalleyId":null}
It will be easier to read when it is run through a JSON formatter.
{
"time": "2023-02-27 11:41:14",
"ip": "87d8edf8cac2b8fd179421b03edcd9c5a2093a79c341964179b8e379faabd324",
"userAgent": "Mozilla\/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko\/20100101 Firefox\/110.0",
"canonicalUrl": "https:\/\/example.org\/publicknowledge\/index",
"assocType": 256,
"contextId": 1,
"submissionId": null,
"representationId": null,
"submissionFileId": null,
"fileType": null,
"country": null,
"region": null,
"city": null,
"institutionIds": [],
"version": "3.4.0.0",
"issueId": null,
"issueGalleyId": null
}
The log files are stored in <files_dir>/usageStats, in the following subdirectories.
| Directory | Description |
|---|---|
archive |
All log files that have been successfully processed into metrics. |
processing |
All log files currently being processed. Log files are moved into this directory when UsageStatsLoader is moving log entries into the temporary records tables. |
reject |
Any log files which could not be processed, usually due to a formatting error. |
stage |
Any log files which are about to be processed. UsageStatsLoader will move all log files it expects to process into this directory before processing them one-by-one. |
usageEventLogs |
All log files which are waiting to be processed. |
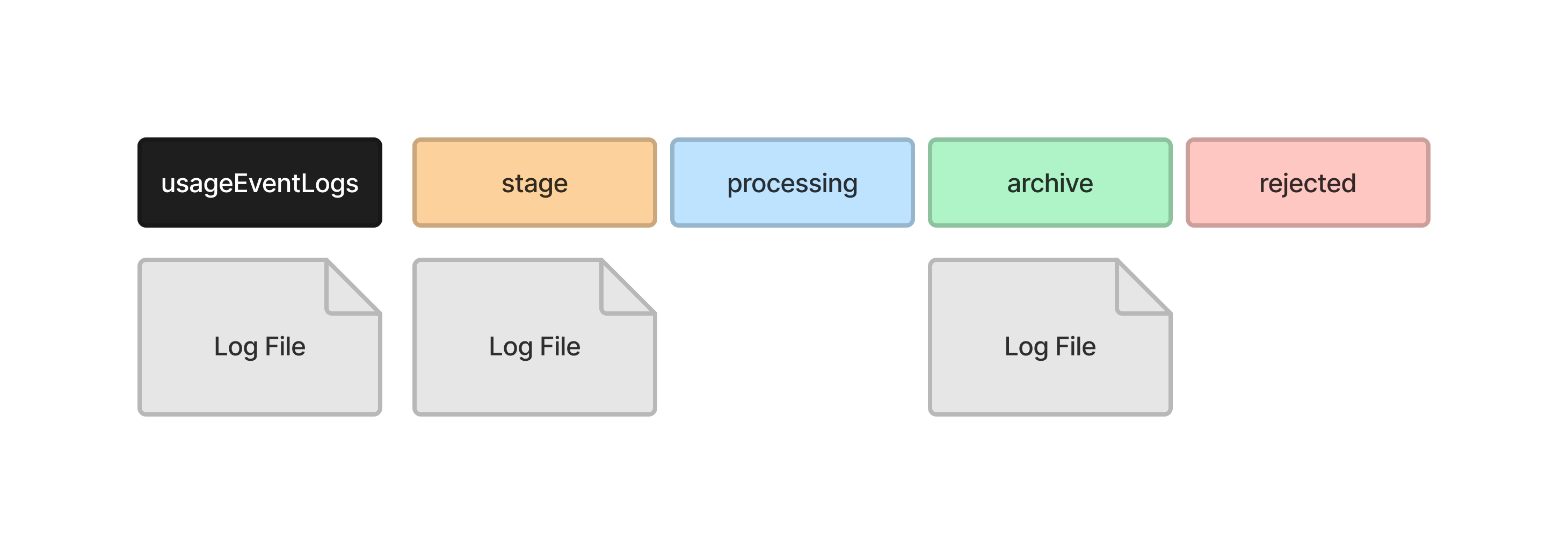
When the scheduled task, UsageStatsLoader, is run, the log files are moved through the directories as they are processed. Consider the following example. There are three log files waiting to be processed.
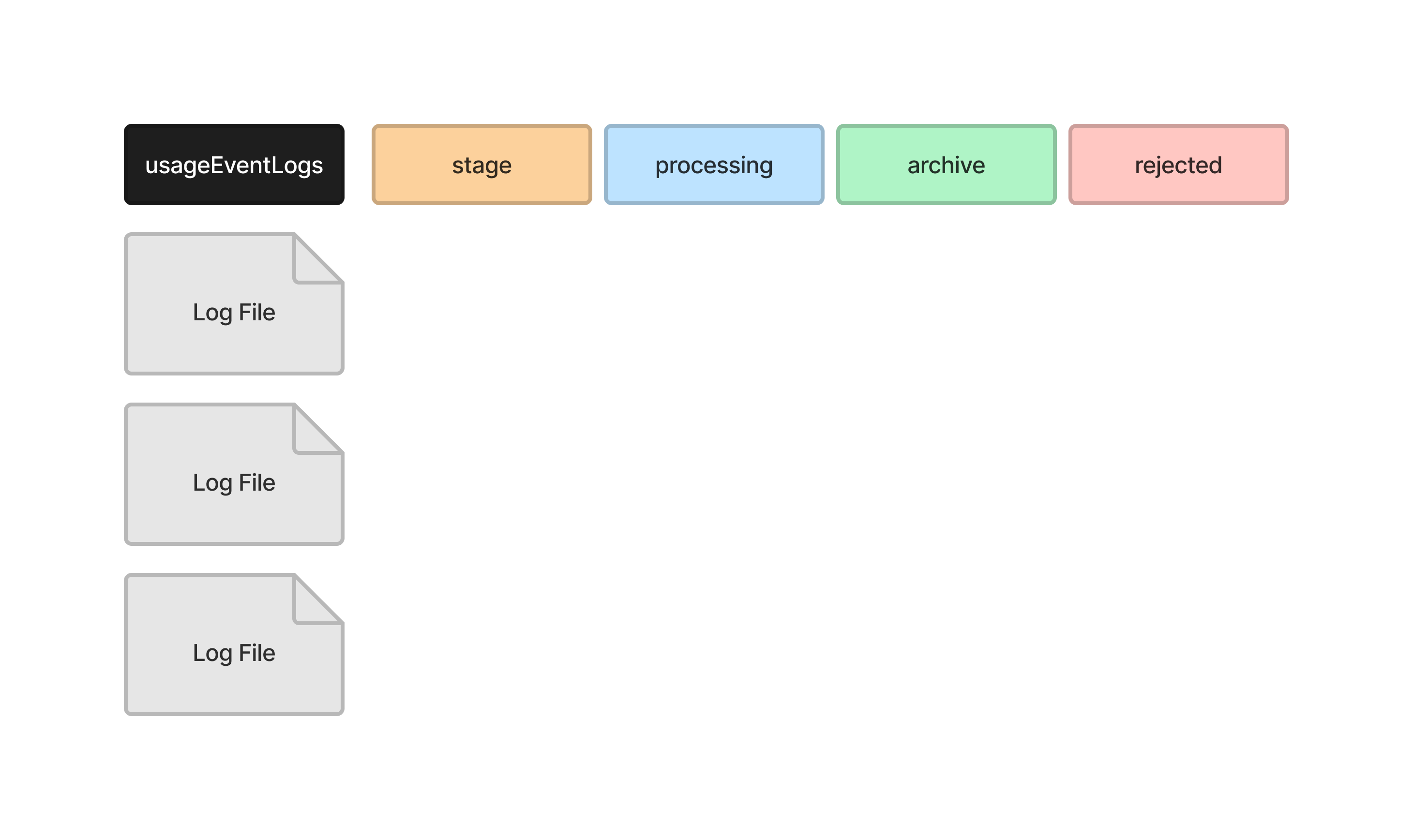
UsageStatsLoader starts by moving all of the files it wants to process into the stage directory. One file is not moved because this file includes logs for the current day, so more log entries may still be written to it.
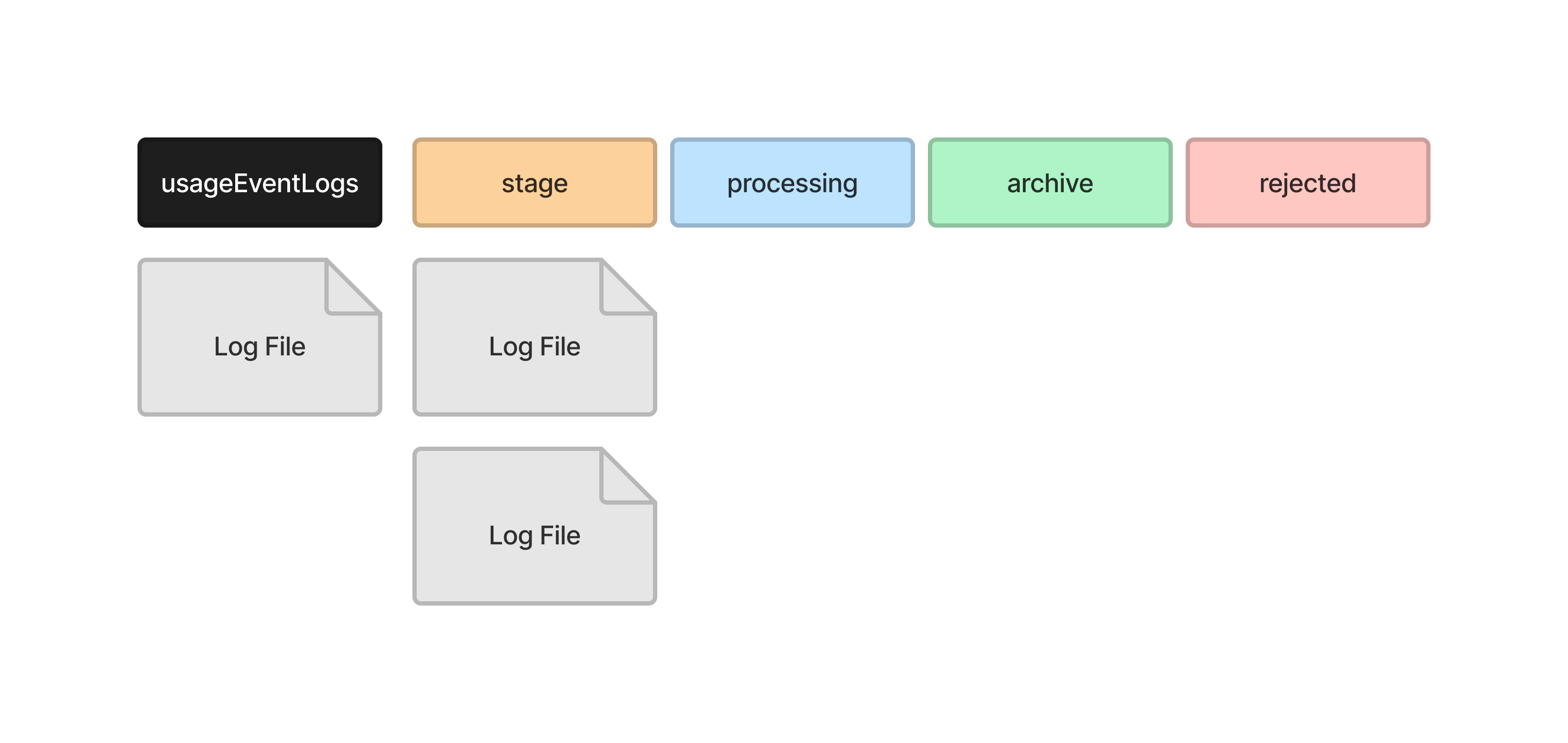
It then moves the first file into the processing directory, where it reads the log entries into the temporary records tables in the database.
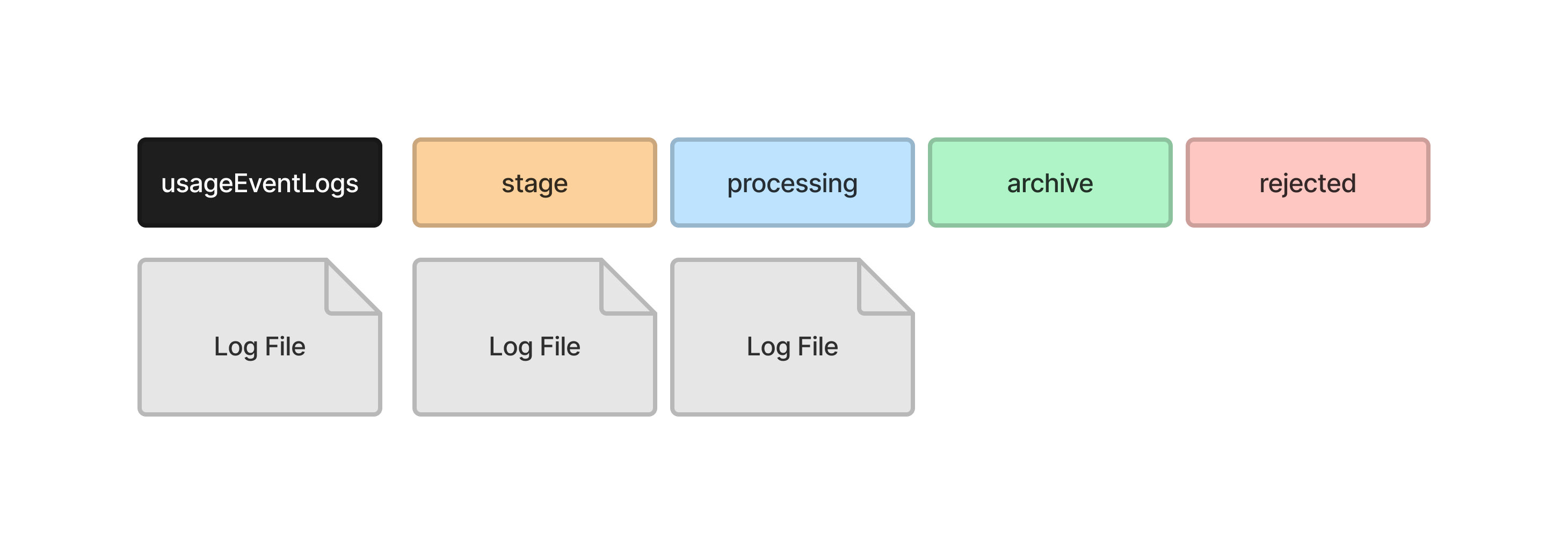
It moves the file into the archive directory when it has finished.
It then moves the next file into the processing directory, where it reads the log entries into the temporary records tables in the database.
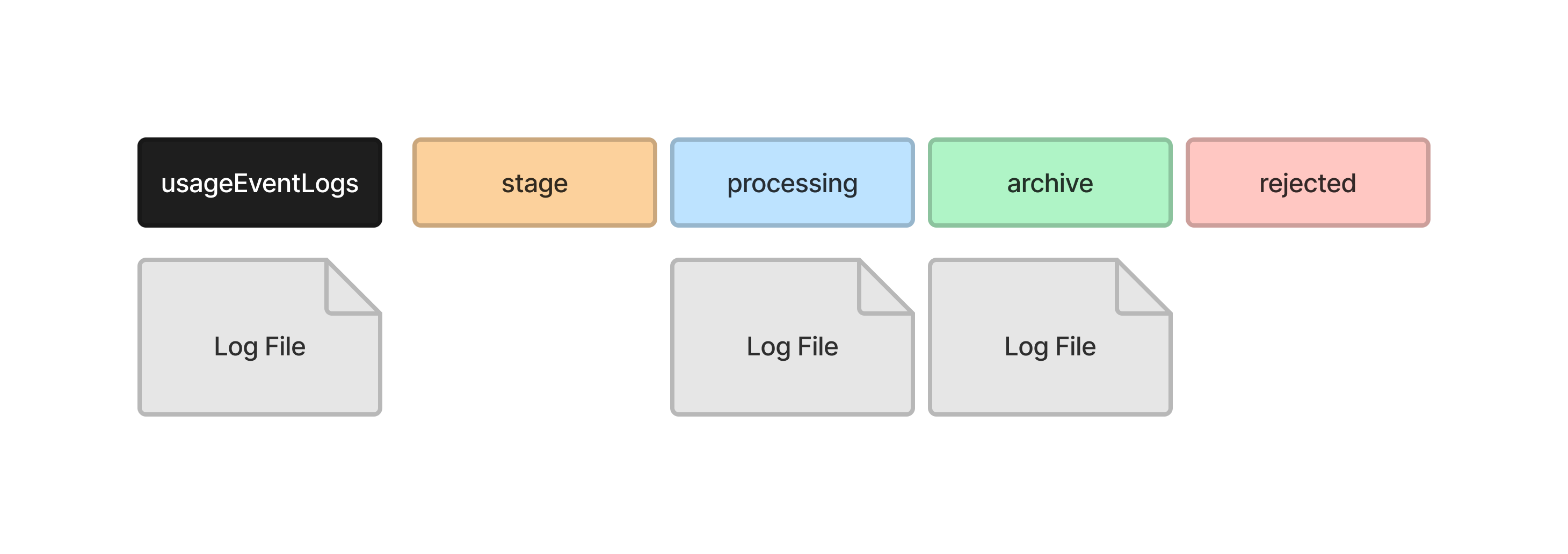
And moves the file into the archive directory when it has finished.
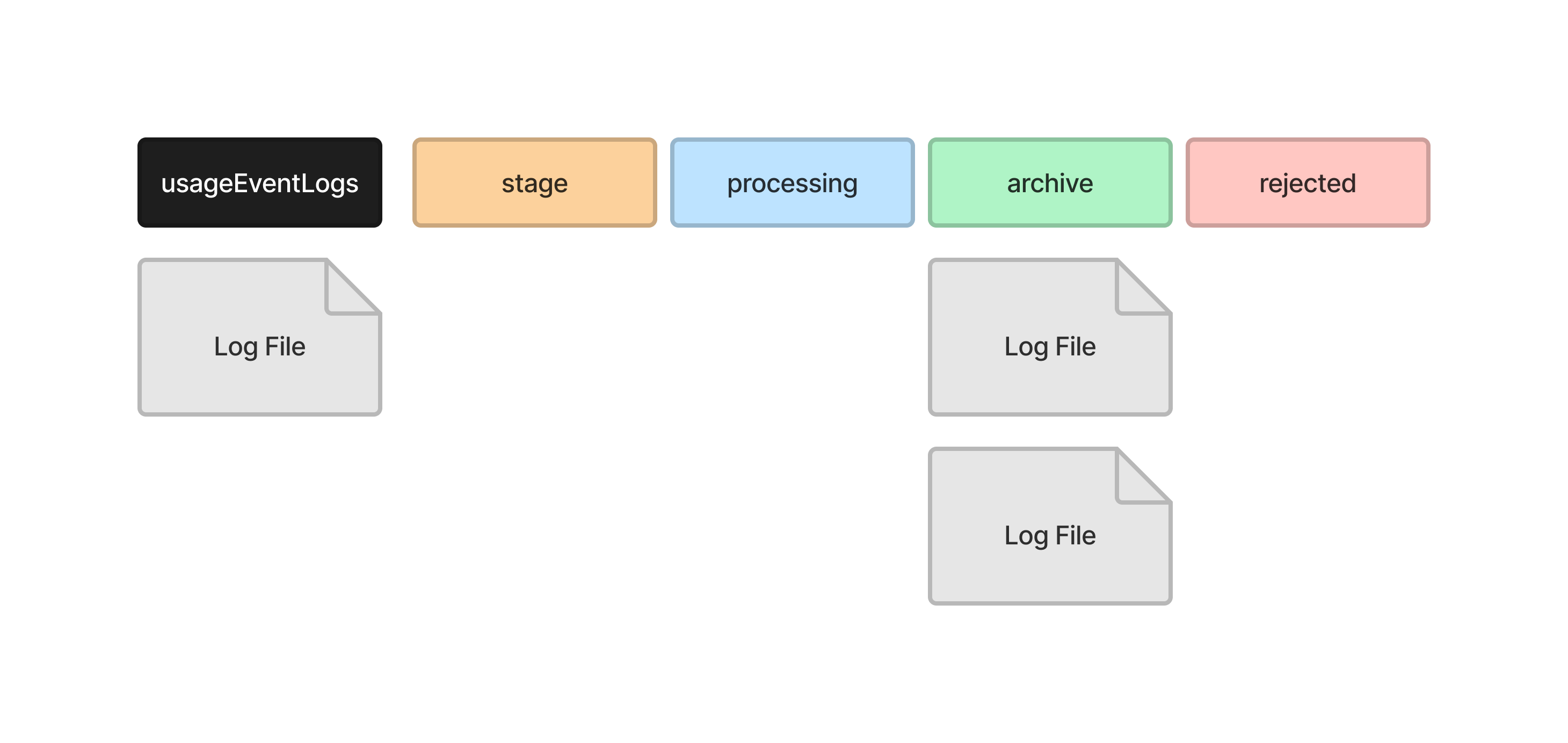
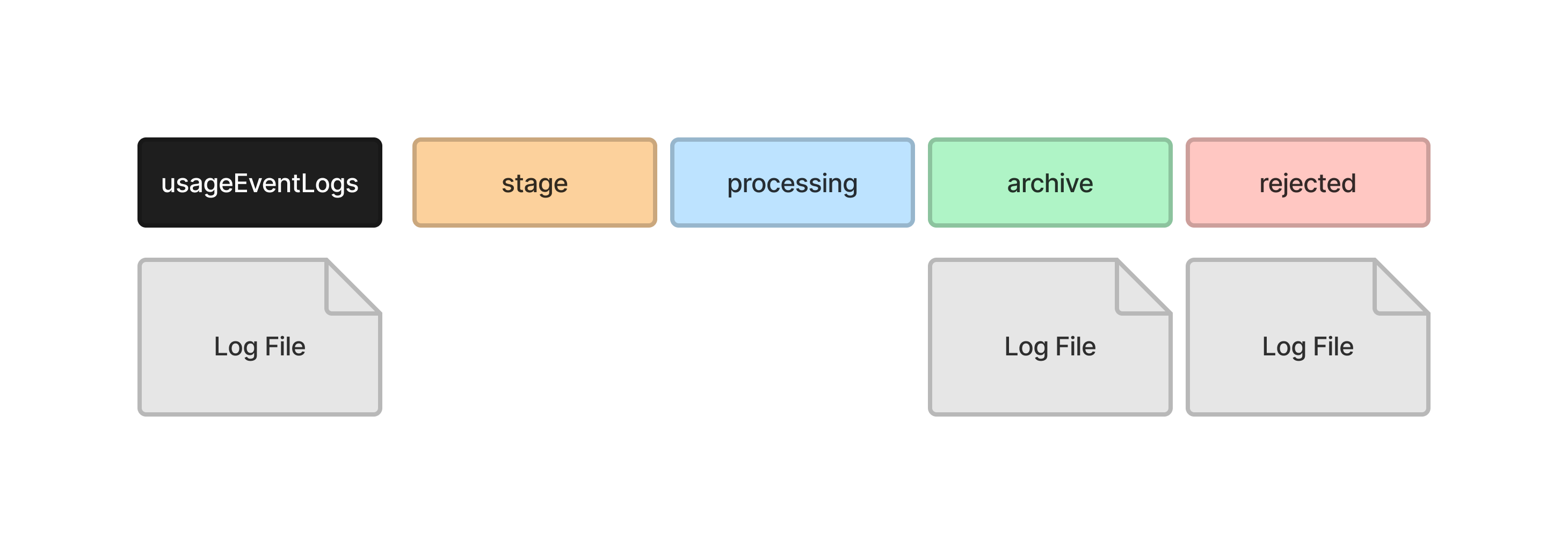
If UsageStatsLoader encounters a problem reading the log file, it will remove any data it inserted into the temporary records tables and move the log file into the rejected directory.
The usage event will be dispatched when a user visits one of the following pages.
| Page | Description |
|---|---|
| Publication | The webpage for any published article, book or monograph, including all versions of that publication. |
| File | A file for any published article, book or monograph. |
| Issue | The table of contents of a published issue (OJS). |
| Issue Galley | The galley of a published issue (OJS). |
| Homepage | The homepage of the journal, press or preprint server. |
| Catalog | The catalog of a press (OMP). |
| Chapter | The webpage for the chapter of a published book (OMP). |
| Series | The webpage of a series in the catalog of a press (OMP). |
Since the UsageEvent is dispatched every time someone visits the website, any task performed in the event or listener will slow down the site. Never access the database, load data, make a HTTP request, or perform any resource intensive task in the event or listener. Add the smallest amount of data that you need to the log and keep all other tasks in a job or scheduled task.
Statistics are initially processed into the *_temporary_records tables of the database. These are then compiled into the final metrics_* tables.
Read a description of these tables in the database reference.
Several service classes are available to access the compiled metrics data for submissions, files, geographic regions, institutions and more. Use these classes instead of going directly to the metrics tables.
For example, get a list of the most viewed publications.
$totals = Services::get('publicationStats')->getTotals([
'contextIds' => [1]
]);
This will return an array of submission IDs and totals.
[
[0] => stdClass Object
(
[submission_id] => 5
[metric] => 1102
)
[1] => stdClass Object
(
[submission_id] => 6
[metric] => 875
)
...
]
The method accepts several arguments to filter submissions by date, section, or a search phrase. For example, here is how to get a list of the top 10 publications of a journal by total visits in March 2022.
$totals = Services::get('publicationStats')->getTotals([
'contextIds' => [1],
'count' => 10,
'offset' => 0,
'dateStart' => '2022-03-01',
'dateEnd' => '2022-03-31'
]);
It can also return publications ranked by the number of downloads of primary or supplementary files, or a specific file type like PDF. Get a list of the top 10 publications of a journal by total downloads of their primary PDF files.
$totals = Services::get('publicationStats')->getTotals([
'contextIds' => [1],
'count' => 10,
'offset' => 0,
'assocTypes' => [Application::ASSOC_TYPE_SUBMISSION_FILE],
'fileTypes' => [StatisticsHelper::STATISTICS_FILE_TYPE_PDF]
]);
Most service classes have a method to view total visits broken down into a monthly or daily timeline. Get a count of monthly visits to all publications in 2022.
$timeline = Services::get('publicationStats')->getTimeline(
StatisticsHelper::STATISTICS_DIMENSION_MONTH,
[
'contextIds' => [1],
'dateStart' => '2022-01-01',
'dateEnd' => '2022-12-31',
]
);
This will return an array like this.
[
[
'date' => '2022-01',
'label' => 'January, 2022',
'value' => 530,
],
[
'date' => '2022-02',
'label' => 'February, 2022',
'value' => 430,
],
[
'date' => '2022-03',
'label' => 'March, 2022',
'value' => 630,
],
...
]
Most of the statistics service classes support the same methods and arguments. View the source code for each service class listed below to see which methods and arguments are supported.
| Service | Class | Description |
|---|---|---|
Services::get('contextStats') |
PKPStatsContextService |
Views of the homepage. |
Services::get('publicationStats') |
StatsPublicationService |
Views and downloads of submissions and submission files. |
Services::get('issueStats') |
StatsIssueService |
Views and downloads of issues (OJS). |
Services::get('geoStats') |
PKPStatsGeoService |
Views and downloads by country, region or city. |
Services::get('sushiStats') |
PKPStatsSushiService |
Metrics according to the COUNTER 5 SUSHI. |
Services::get('editorialStats') |
StatsEditorialService |
Stats about editorial activity. See Editorial Stats. |
All of the API endpoints for statistics can return the data in JSON or CSV format. When adding an API endpoint that delivers statistics, look for the Accept header in requests.
$useCsvResponse = str_contains(
$slimRequest->getHeaderLine('Accept'),
APIResponse::RESPONSE_CSV
);
The APIResponse has a helper method that can be used to return CSV data.
use PKP\core\APIResponse;
use Slim\Http\Request;
public function getMany(Request $request, APIResponse $response): APIResponse
{
// ...
$useCsvResponse = str_contains(
$slimRequest->getHeaderLine('Accept'),
APIResponse::RESPONSE_CSV
);
if ($useCsvResponse) {
return $response->withCSV(
$items
$columnNames,
$itemsMax
);
}
return $response->withJson([
'items' => $items,
'itemsMax' => $itemsMax
], 200);
}